IAS Technology Insider is dedicated to discussing computer science, software engineering, and emerging technologies. From deep dives into machine learning algorithms and cloud computing architectures to discussions on cybersecurity trends and data analytics methodologies, our tech experts offer insights and analyses that resonate with enthusiasts and professionals alike.
By Feng Fan, Data Engineer, IAS
Recently I worked on a project to evaluate different left-join options for a Spark application we are building to modernize our largest data pipeline. The pipeline processes about 2B events per hour, creating a data set of about 0.5B records. There was a long running left-join operation that took 20 minutes to finish using Pig over MapReduce in the old pipeline. My task was to benchmark this left-join operation with different Spark join options. This article shares the learnings I gathered during that project.
Dataset Sizes and Test Environment
On the left side of the join we had a big dataset of 820 GB of compressed TSV files. On the right side we had 650 MB of compressed lookup data. There were about 51MM lookup IDs, but less than 350K distinct IDs would be selected at any specific run of the left-join. To reduce the size of lookup IDs I tried to find some filters to predict which IDs could be excluded, but was unable to identify a good predictive filter.
To run the tests I set up a small EMR cluster with 30 m5.4xlarge core nodes (about 500 v-cores) and ran Spark 2.4.7. Using the r5 or r6 class of instances would further improve performance. My objective was to compare different join options. We later verified the findings with a much larger cluster and found that the performance improved linearly to the cluster size.
How I Measured Performance of Left-Join Operation
As Spark optimizes and lazily executes declarative data transformations, I couldn’t directly benchmark the join operation. I measured the performance of a baseline operation of reading the 820GB data set and writing out the resulting data set. For each Spark join option I then measured the performance of reading datasets, conducting the left-joining, and writing out the joined data set. The timing difference with the baseline operation was the approximate cost consumed by each left-join operation.
Here is the code example of evaluating performances of the baseline operation and the Sort-merge join operation.
Code example 1: estimate join performance
At first I simply did a row count on the resulting dataset instead of writing out the whole dataset when I benchmarked the join timing cost. I noticed that the Spark Optimizer only shuffled a very small set of columns needed for the join. In order to get a more accurate approximation of the full processing cost I ended up outputting the whole dataset. This forced Spark to shuffle all columns, which was close to our use case.
Evaluated Join Operations
I evaluated three types of join operations:
- Sort-merge Join: This is the default join operation in Apache Spark. After shuffling, co-located partitions from both datasets are sorted by the join key and are then merge-joined (see more details here). Its performance is largely determined by the size of the data being shuffled and sorted.
- Broadcast Join: In this operation Spark sends (broadcasts) the smaller data set to all nodes. The performance of that join depends on the size of the data set that is broadcast (see more details here). The lookup dataset’s size was about 600Mb in serialized format; it’s too big for Broadcast join. I wanted to try out the broadcast join and see what would happen.
- Read from Memcached: A co-worker suggested a creative idea to load the lookup data in Memcached and conduct the join by looking up Memcached with local caches in the executors. I implemented the idea with a Spark SQL UDF; it could also be done with RDD transformation. There was no performance difference between the two methods. Here is the coding example of the Spark SQL UDF: Code example 2: Spark SQL UDF that looks up Memcached
Findings
Here are the benchmarking results of the various join types. The Sort-merge join shuffled 1170GB of data. Compared with the baseline operation, it’s estimated it took 5.4 minutes to finish; there were no data shuffles in the case of Broadcast-Join and Memcached lookup. They only cost a few extra seconds to finish.
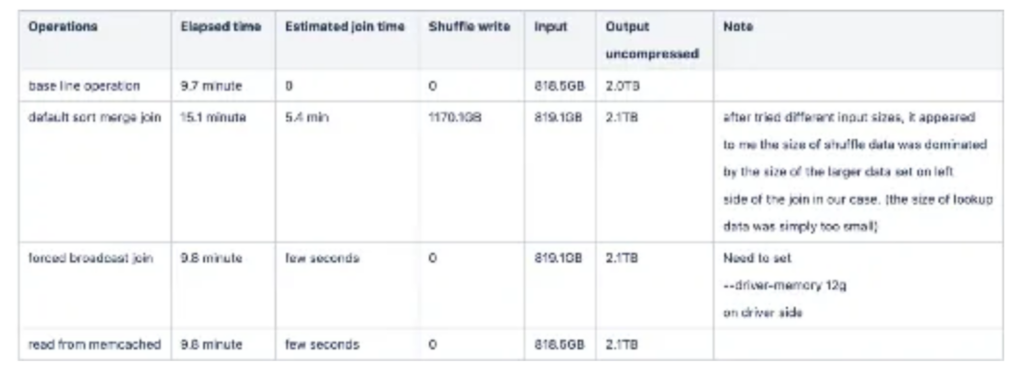
I identified several interesting findings:
- Sort-merge Join Performance determined by the larger Data Set in this case: The performance of the sort-merge join is mostly related to the size of data shuffled, also in this case the size of my large fact dataset was 1000 times bigger than the small lookup dataset. It suggested I needed to apply strategies including conduct all filtering first and conduct pre-aggregation to reduce the size of the larger dataset. Further benchmarking suggested that the performance gained was linear to the size reduction of the input dataset.
- Beware of skewed Data: Skewed data is the uneven distribution of shuffled data across partitions causing one or more partitions to hold a disproportionately large share of the overall dataset. You can check for this by looking for those few tasks that always take much longer to finish in UI. In my case the data was evenly distributed.
- Broadcast Join can be memory intensive and fast: This operation can create OOM errors on the driver site. In my case I avoided this by setting the Spark option ‘ — driver-memory 12g’. However, the broadcast join operation showed impressive performance.
Memcached Lookup has no memory pressure and is fast: All my experimentation was done in AWS. It turned out Amazon ElasticCache for Memcached provides submillisecond latency when I set them up in the same subnetwork. Performance was excellent as long as the lookup frequency was kept under control. In my case all the executors together needed to lookup no more than 350K unique IDs.
Conclusions
This project turned out more interesting than I originally thought and provided excellent insights, namely:
- The Spark optimizer is really smart: It ignores columns not used in downstream operations.
- Merged join/skewed join scale linearly: Performance of sort merge join or skewed join are mainly determined by size of the data being shuffled.
- Broadcast join consumes a lot of memory: Broadcast join by default sends all data to the Spark driver. This creates a lot of memory pressure on the driver side.
- Consider Memcached: When the network latency is low and the number of lookups is limited, looking up Memcached with local caches inside executors is an excellent choice.
- Less control over memory: Because of the declarative style of Spark programming, we can’t directly control the release of cached data from the executors when we use broadcast join or Memcached lookups.
Through these experiments a picture emerged for when to use which join strategy which you can see in Figure 2.

I am glad I went through this exercise and was able to learn about various Spark join strategies I could apply in my applications. At Integral Ad Science we encourage experimentation and I am always amazed what interesting insights I am able to learn.
Article originally published on March 15, 2021.


