IAS Technology Insider is dedicated to discussing computer science, software engineering, and emerging technologies. From deep dives into machine learning algorithms and cloud computing architectures to discussions on cybersecurity trends and data analytics methodologies, our tech experts offer insights and analyses that resonate with enthusiasts and professionals alike.
By Yuvaraj Mahendran, Principal Engineer, IAS
At Integral Ad Science, with billions of events hourly, milliseconds can make a difference in down-stream processing. Is Apache Pulsar ready to replace Kafka as our go to streaming data provider? We put it to the test.
Goal
Our main goal was to expose and make data available for down-stream processing within milliseconds from the actual event happening.
Candidates for experimenting
Apache Kafka is a framework that’s been in the market since 2011, and has stood the test in time in and outside IAS. Given that we have our core-pipes already running in AWS, MSK (Amazon managed Kafka) was a natural choice. However, there has been a good amount of chatter about the relatively new framework, Apache Pulsar, to address the exact need as well. While Pulsar comes loaded with features, here are the main and differentiating (from Kafka) features that attracted us the most:
- Segments vs Partitions
- Geo Replication
- Tiered Data Storage
- High Throughput
- Access Restrictions to Topics
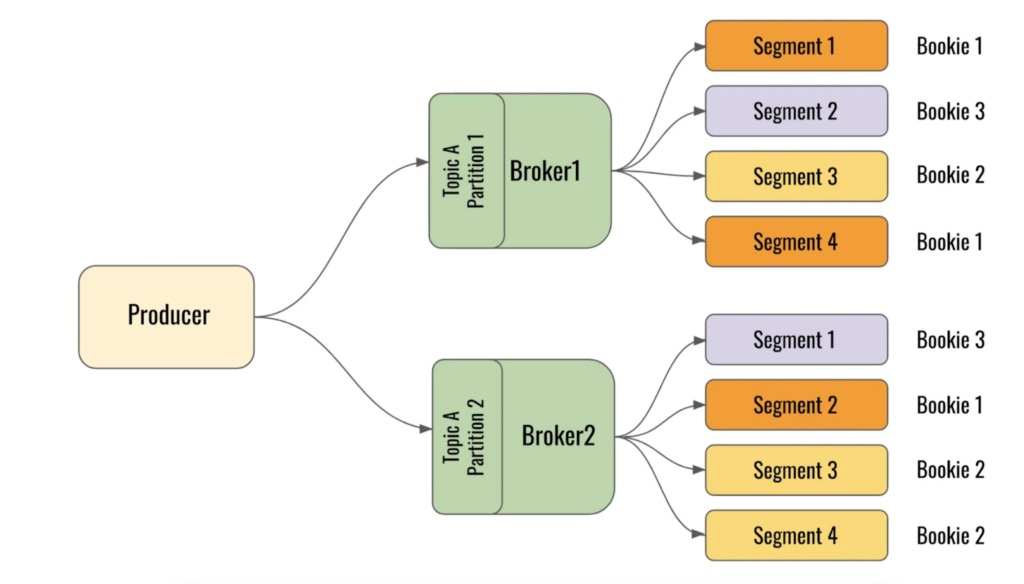
Segments vs. Partitions
In Pulsar, just as in Kafka, messages from producers are sent to brokers against specific topics. For horizontal scalability, both Kafka and Pulsar support partitions within topics thus enabling messages to the same topic residing in different brokers in the same cluster. This is where the similarity ends.
Kafka ensures that each partition is assigned to a specific consumer within a consumer group. This essentially translates to not being able to have more consumers than the partition size thus enforcing an artificial limit to the number of consumers one could have for a given topic, unless of course we increase the partition size — which comes with its own caveats.
Pulsar, on the other hand, has the concept of Segments within partitions and consumers are allocated segments, thus enabling multiple consumers to connect to the same partition. This model was more enticing for us because of the increased horizontal scalability model that it presented.
Topic-Segment Layout in Pulsar
Geo Replication
Because of our global presence at IAS, we needed our regional servers to send events to clusters in their local regions for low-latency writes. These events could then be asynchronously replicated over to a central location. Even though Kafka provides Mirror Maker 2 (much better than the earlier version), this is a separate service that needs to be run, maintained, monitored, and upgraded.
Pulsar, on the other hand, came with geo-replication out of the box. With just a few config settings, geo-replication could be enabled and events would automagically be replicated to our central pulsar cluster.
Tiered Data Storage
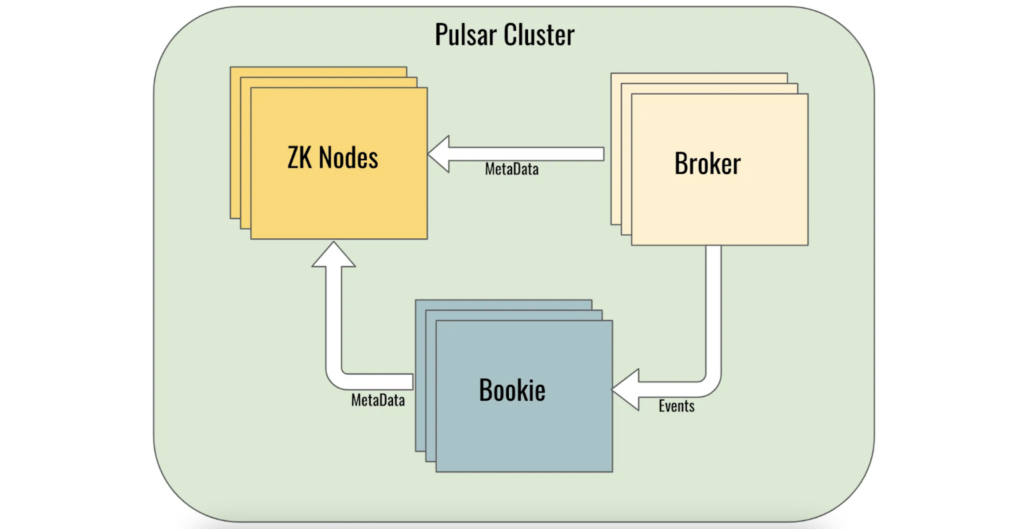
Kafka stores the data in brokers themselves and hence when brokers go down or when a new broker is added, data needs to be shuffled between brokers invariably. While all the data shuffling happens automatically, there definitely would be some performance degradation during those times. Unlike Kafka, Pulsar separates data from brokers and stores them in the Bookkeeper cluster. This allows for easy scaling of brokers in Pulsar as they are essentially stateless. Also the storage layer can be extended to use S3 storage option.
High Throughput
Pulsar touts higher throughput compared to Kafka in their documentation. Can Pulsar back up their touted end-to-end performance and beat Kafka? We put it to the test.
Access Restrictions to Topics
IAS needs to enforce access restrictions on partner data for security reasons and the only way to achieve this in Kafka is by having separate clusters for different partners’ messages. On the other hand, Pulsar allows us to enforce access restrictions at a topic level or at namespace level. Namespace is nothing but a logical group of topics. Hence with Pulsar, it would allow us to have a single cluster with multiple topics and different access restrictions.
Analysis Criteria
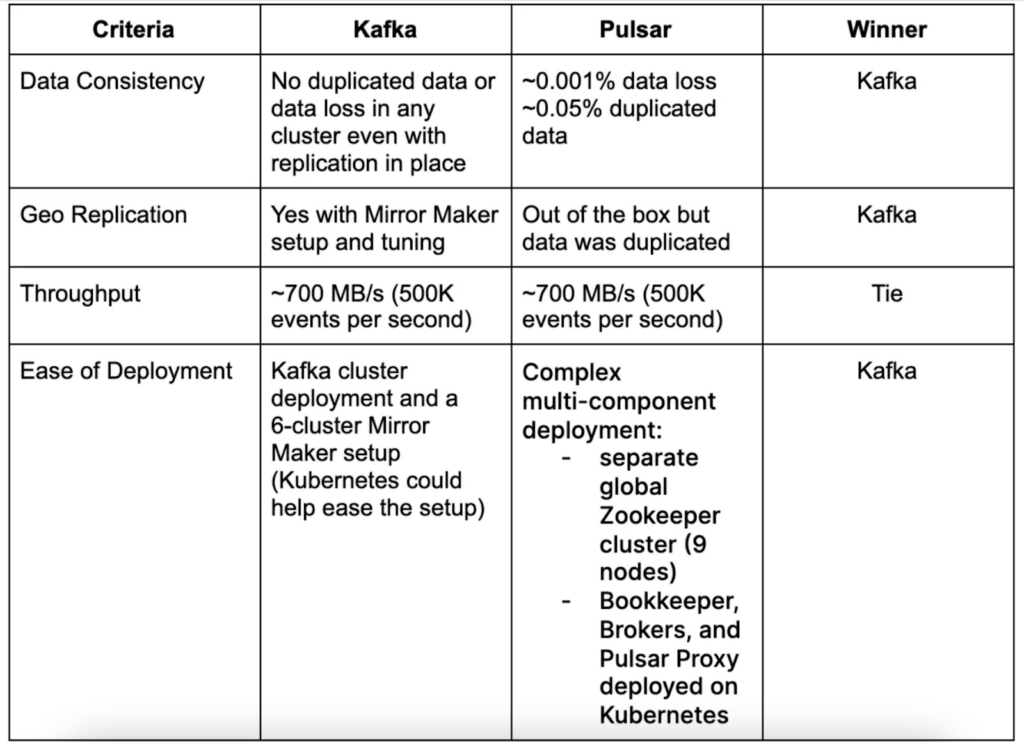
We measured Kafka vs Pulsar on the following criteria:
- Data consistency
- Geo Replication
- Throughput
- Ease of deployment
Cluster Setup

Results
Conclusion
We decided to remain on Kafka for now. Though we didn’t make a change this time, it’s critical that at Integral Ad Science, we review and test new technologies to find opportunities for improvements to process our massive dataset at scale and to predict and satisfy client needs.
Article originally published on January 4, 2021.


